2025-04-01
生成式人工智能的突然爆红,除了给算力芯片提出了更高的要求以外,传统系统设计无法满足计算需求的缺点也愈发明显。
在过去的发展中,内存和I/O的扩展能力本已远落后于计算密度的增长,平均到每个核心的内存和I/O带宽更是持续下降。而随着AIGC时代的到来,内存需求大幅增加,同时也产生了梯度数据聚合与分发等海量I/O通信需求。这个时候,就需要新的架构来缓解系统内存和I/O瓶颈,实现数据处理规模、并行处理能力和系统算力提升。
所谓CXL,也就是Compute Express Link。作为一种开放标准的高速互联协议,CXL的推出主要是要解决计算器件和内存之间的互联问题,旨在改善处理器与加速器、内存扩展设备等之间的通信。
从技术上看,CXL是通过现有的PCIe(Peripheral Component Interconnect Express)物理层传输信号,但在协议层面上引入了新的特性和改进,以显著提升系统中处理器、加速器和内存设备之间的数据交换效率和一致性,使得资源共享具有更低的延迟,减少了软件堆栈的复杂性,并降低了整体系统成本,为高性能计算和大规模数据处理提供了更为强大的支持。
自2019年首次发布以来,CXL在过去几年里已经演进到了CXL 3.1标准。在适用范围方面,也从一开始的仅支持有限功能,增加到对横向扩展 CXL 进行了额外的结构改进、新的可信执行环境增强以及内存扩展器的改进。
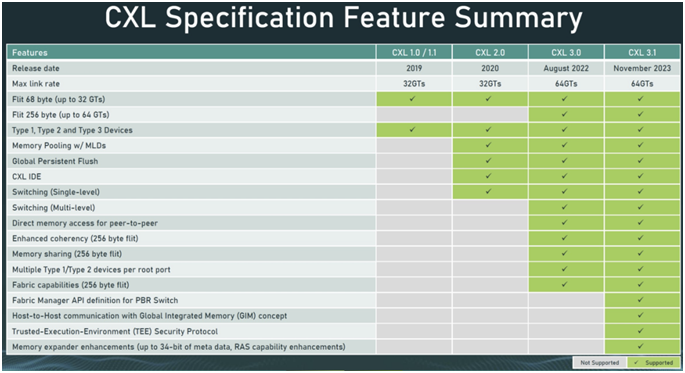
具体而言,CXL拥有以下三个关键特征
■ 统一的内存模型:CXL支持三种协议,分别是CXL.io、CXL.cache和CXL.memory。其中CXL.io主要用于传统的I/O操作,与PCIe类似;CXL.cache和CXL.memory则提供了缓存一致性和内存访问能力,使得CPU与加速器或内存扩展设备之间能够共享和一致性地访问内存。这对于加速器(如GPU、FPGA)而言尤为重要,因为它们可以更有效地访问系统内存,而不必通过缓慢的I/O通道。
■ 缓存一致性:CXL允许处理器和外部设备(如加速器)共享相同的内存空间,并保持缓存的一致性。这意味着数据在不同设备之间传输时不需要频繁复制或同步,从而提高了性能。
■ 高带宽低延迟:通过优化的协议栈,CXL在维持高带宽的同时还能提供低延迟的通信。
这使得其在需要快速数据交换的应用中非常适合,如AI加速、数据分析等。相比于传统的基于RDMA的分解内存架构,CXL可以实现纳秒级的低延迟,相比于NVDIMM的非易失性内存,其时延也低几个数量级。
与其他互联协议不一样,CXL的关键差异点就在于其硬件支持cache coherency。也正是因为具备这样的特性,CXL可以实现CPU与加速器或内存扩展设备之间能够共享和一致性地访问内存,真正实现机架级的分解内存解耦架构。除了CXL协议最初设想的用于CPU-GPU互相以cacheline颗粒度互相访问对方内存并可缓存,CXL还能很好地解决LLM时代内存容量、成本、利用率等挑战。
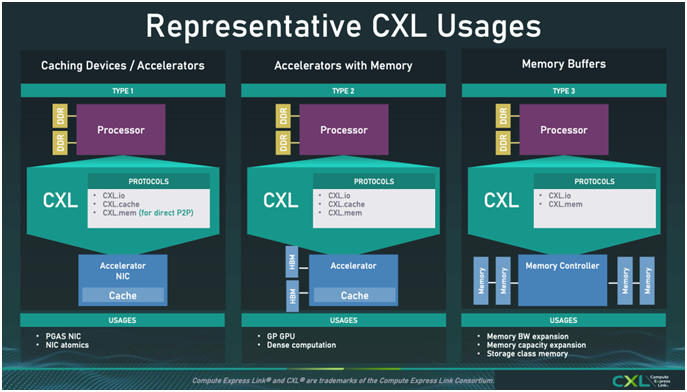
如上图所示,CXL有三种典型用例。知名分析机构Yole更是乐观预期,到 2028 年,CXL 市场总收入将增长到 150 亿美元以上。其中,DRAM 将构成 CXL 市场收入的大部分,到 2028 年市场收入将超过 120 亿美元。除此以外,CXL 控制器和CXL交换机也将在市场中迅速发展。

